Overview
Since 2017
- A Chinese query TV bot.
- Reinforcement Learning based task-oriented intelligent conversational bot.
- It knows EVERYTHING about videos. (70,000+ richly structured data)
- You can ask for anything about videos with several intent functions.
- You can try our bot via android app or Website.
- Our app supports Google Speech API.
Want some TV?
KUBO YOUR LIFE !!!
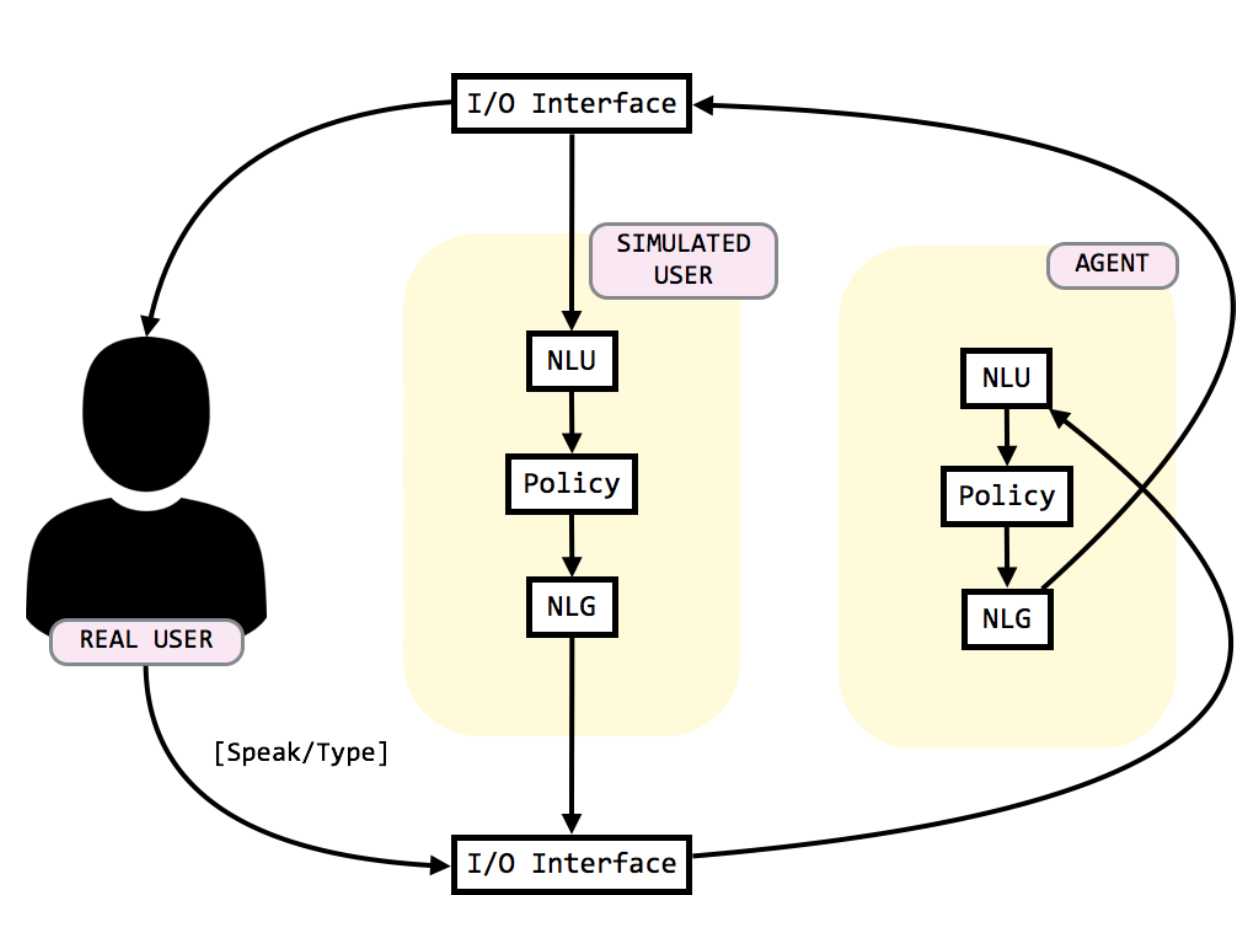
⇧chatbot architecture
Ontology
Data
Data are from www.123kubo.com. We use SQLite to construct our database.
Database
There are 4 tables in the database. One for the basic information of each movie, and the other three are for dynamic numbers of actors, movie types, and movie aliases.
Slot
#: 14
| actor | status | content | year | rating_count | rating_score | movie_type |
| location | update_time | hot | alias | playcount | exp | reward |
Intent
#: 18
| alias | actor | status | rating_count | rating_score | content | update_time | year | hot |
| movie_type | location | exp | playcount | reward | greeting | asking | inform | no_intent |
Natural Language Understanding
Data Format
Typically, word segamentation is used for Chinese text, which is no apparent margin between words.
But in this task, there are many proper nouns in the data, such as a movie name or a actor name.
This characteristic makes vocabulary very sparse and leads to low performance of NLU.
To solve this problem, we use character-level seqeunce format for more dense vocabulary distribution. Actually, a Chinese character contains very rich information (richer than an English character contains). So character-level format is quite suitable for Chinese data. Below shows an example of training data, including slot tags of every character and an intent of this sequence.
We use 100,000 samples as training data, and 50 human-labelled sentences as testing data.
| sentence | 我 | 要 | 找 | 全 | 職 | 獵 | 人 | 的 | 評 | 分 | intent |
|---|---|---|---|---|---|---|---|---|---|---|---|
| slot label | O | O | O | B-alias | I-alias | I-alias | I-alias | O | O | O | request_rating_score |
Model Description
Seq2Seq model with LSTM cell, jointly learning intent prediction and slot filling.
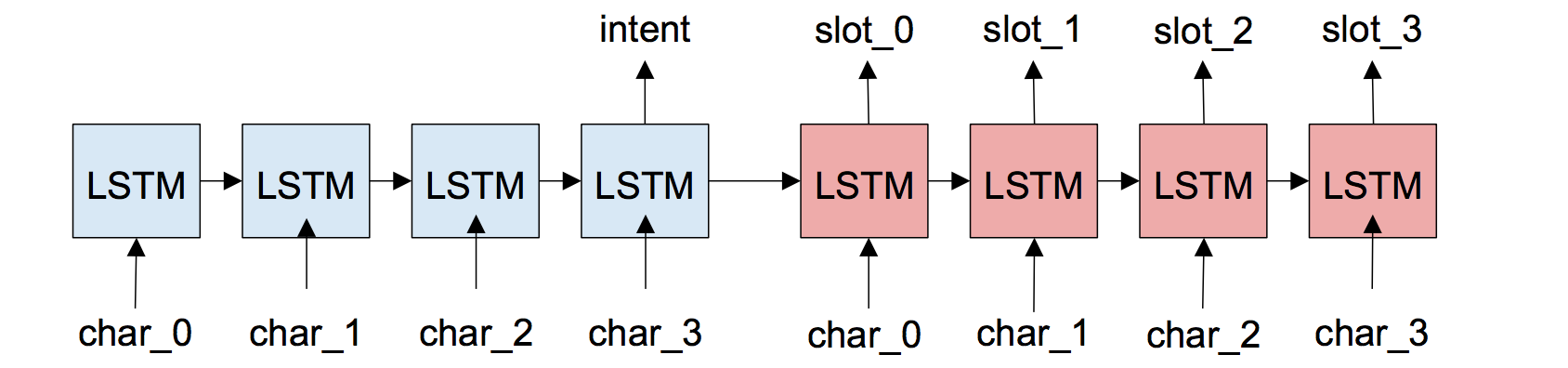
Use encoder to predict intent and use decoder to predict slot type at each position.
| Training | Testing | |
|---|---|---|
| F1 Score | 0.997 | 0.899 |
| Intent Accuracy | 0.998 | 0.952 |
⇧NLU F1 score and accuracy
Noisy Training Data Generation
In order to let our NLU model to be more robust, we design a noisy channel to randomly drop characters in each pattern. We assume that human might not know the exact pattern that we had designed or even make some mistakes when they talk to our TVBot. Therefore, noisy training data will help us deal with these problem. The following sentences shows that one intent can generate many different results.
- 我要找全職獵人的電影 (origin pattern)
- 要找全職獵人的電影
- 全職獵人的電影
- 要全職獵人的電影
Query Expansion
In our experiment, we found that it is very difficult to match user's query with our DB format. In other words, user doesn't know the exact name that we had store in our data base. For example, if user wants to find "殭屍片" and with the query "殭屍", but the movie type of "殭屍片" in stored our data base was "恐怖片". In this case, it is almost impossible to find the right answer for this query. To solve this problem, we use query expansion to expan user's query to any possible entity that stored in our data base. Moreover, we also caculate the characters hit rate to find the most possible mapping entity for those queries which can't find the exact mapping in our mapping table.
Dialogue Management
Dialogue State Tracking
Rule-Based Model
We use rule-based method for dialoue state tracking because it can be well controlled and easily formatted to query of Database.
We define State as a table with all available slot types and their contents. To handle the slot types which may contrain multiple contents, such as actor and movie type, every slot type has a set to store all possible contents. The table below is an example of out state. _UNKNOWN_ of year means that the agent asked user for year, and user answered "I don't know"; The empty content of status means that the agent hasn't get any information of status from user.
| slot type | content |
|---|---|
| actor | 田淼, 肖彥博, 吳曦 |
| location | 中港臺 |
| movie type | 懸疑, 恐怖 |
| rating score | 7.2 |
| year | _UNKNOWN_ |
| status | |
| ... | ... |
Query Strategy
For those numeric content, we query them as lower bound.
We format state by the rule: ignoring _UNKNOWN_ and empty content, we use or operation for contents of the same slot type, and and operation between different slot types. So the example above can be formatted to:
(actor==田淼 or 肖彥博 or 吳曦) and (location == 中港臺) and (movie type==懸疑 or 恐怖) and (rating score>=7.2)
Note that it is a "soft" strategy because of the "or" operation, we use this strategy to decrease mistakes of query contraint caused by the error of NLU.For some slot types e.g., alias and content, we support fuzzy search so that we can use query (alias==獵人) to get results (alias==全職獵人).
State Tracking
we update agent state by an user action (classfied by NLU model). For updating, we just append the slot content of action to corresponding slot type set of agent state. Because the "soft" query stratefy, we don't need to find out the error of a slot type set. Actually, we can't know which content is "error", even if the content is from a "confirm", it can still be wroung classfication by NLU.
| slot type | content before | user action | content after |
|---|---|---|---|
| actor | 田淼, 肖彥博, 吳曦 | 王聃 | 田淼, 肖彥博, 吳曦, 王聃 |
| location | 中港臺 | 中港臺 | |
| movie type | 懸疑, 恐怖 | 懸疑, 恐怖 | |
| rating score | 7.2 | 7.2 | |
| year | _UNKNOWN_ | _UNKNOWN_ | |
| status | 完結 | 完結 | |
| ... | ... | ... | ... |
State Similarity
We format query, search from database and we get a lot of results, but we can't return all results to user (user may only want top K results). We have to rank those results by some score, so we define "state similarity", which is average of the similarities of slot types. Because slot types contain numeric values and text values, we define "how close to the value in state" as similarity of numeric value and "how many hits to the value in state" as similarity of text value (all scores are normalized to 0~1).
Dialogue Policy Maker
State Vectorization
To implement reinforcement learning, we need some mechanism to represent the state, then the encoded state will be the input of RL.
The most direct way is to encode a state to a vector.
We use following state features for vector representing.
Those features will be ultimately transformed to vectors, then concatenated to a long vector.
- Action History
We stored every user's action & agent's action, and we transform user's action & agent's action to vector.
Because every action is based on former actions, so we merely extract the most lately action respectively. The most lately one is enough to contain history information.
We use one-hot format to represent the intent of action, and use bag-of-words format to represent the slots of action.Action
intent slot_types slot_contents request_alias actor、movie_type 劉德華、動作 intent vector (one-hot)
intent type ... request_alias ... value 0 1 0 slot vector (bag-of-words)
slot type ... actor ... movie ... value 0 1 0 1 0 ⇧How history works
- Turns
The information of dialog turns will be used, too.
We set a zero vector with length fixed to max_turns.
If the current dialog turn is N, we set vector[N] to 1.
This feature can help reducing # of dialog turn during reinforcement learning.if current dialog turn = 4, vector[4] will set to 1
index 0 1 2 3 4 ... max_turns-1 value 0 0 0 0 1 0 0 ⇧How turns works
- Knowledge-based Features
We also make the best of current conditions stored in state.
If there're K conditions provided by user, we will query the database with those K conditions respectively.
We also query the database with those K conditions simultaneously.
Our database will return # of data that meets the given condition.
The # of data will then transformed to two represented formats: scaled count and binary.
Scaled count means to divide the # of data by a constant (set to 100).
Binary means setting the value to 1 if the # of data is greater than zero for the given condition(s), else set the value to 0.
This feature can help the network trained by reinforcement learning to get better judging ability of whether to request or confirm.Current State
slot actor movie_type ... value 羅翔翔 娛樂 (unknown currently) We query the database for # of data with
(actor == 羅翔翔)
(movie_type == 娛樂)
(actor == 羅翔翔) and (movie_type == 娛樂)⇧How Knowledge-based works
Reinforcament Learning-Based Policy Model
We use actor-critic model as our policy model, which contains an actor model and a critic model. The input of the both models is the vector of current state. The output of actor model is the probabilities of agent intents, which means agent action, and we will append the slot content after intent decision; the output of critic model is the predicted reward of agent intents. The Figure below shows the whole structure of actor-critic model.
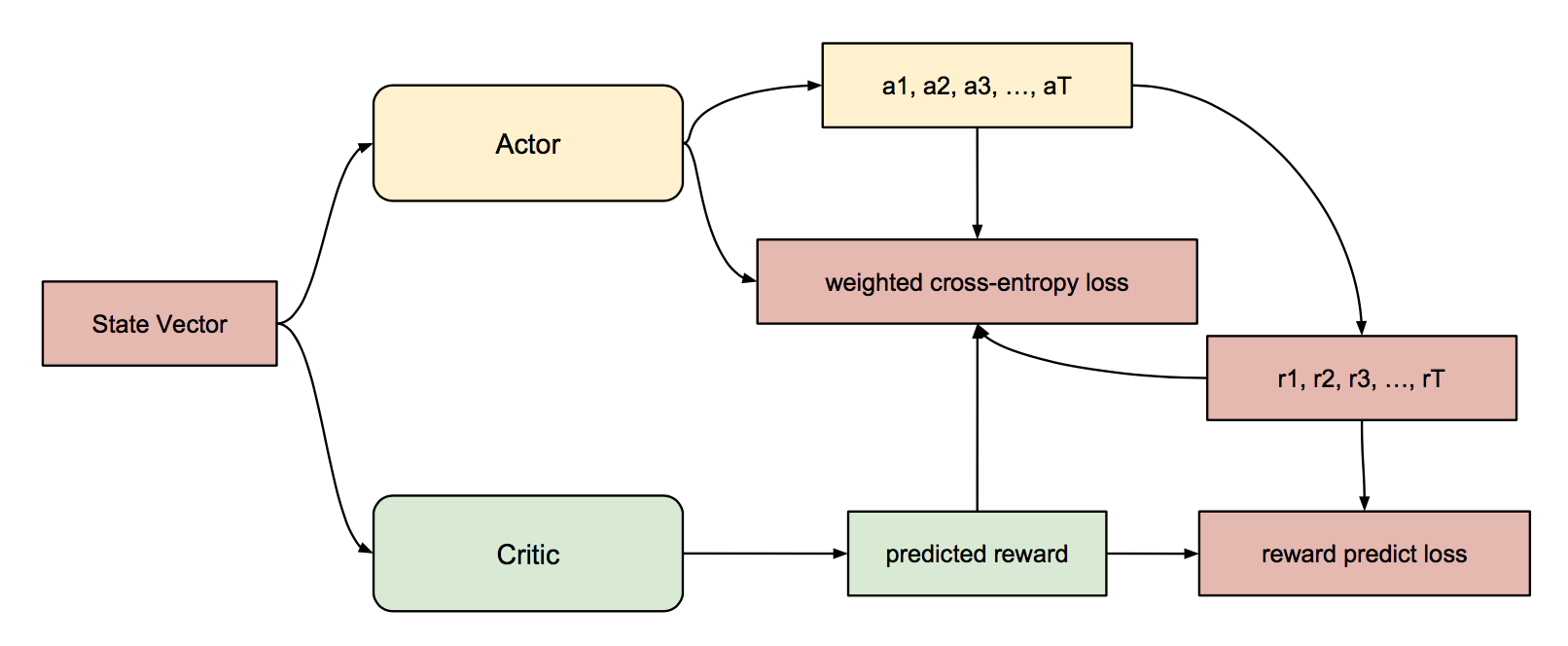
- Reward
We define our reward function as:
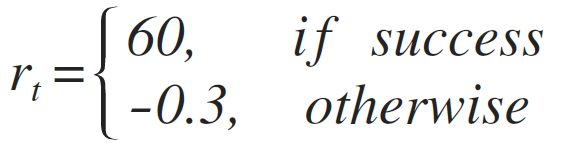
For success, we give high reward and penalty for each turn so that the model prefers a short successful dialogue. - Critic
Out Critic model is used to predict reward (notated as V below) given a state vector. We use square error to approximate true reward. That means we try to get an average reward given a state vector, which is known as Monte Carlo error.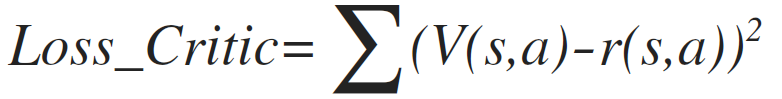
⇧critic loss - Actor
Our actor model tries to maximize the expected value of reward. Usually, actor model is updated with reward minus a "baseline" (notated as b). In actor-critic, we use the output of critic model as the baseline.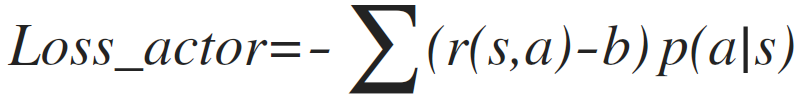
⇧actor loss of vanilla actor model 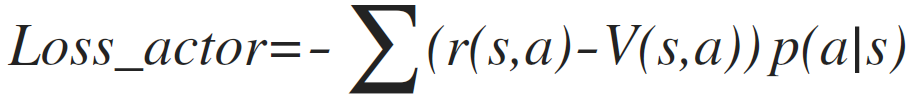
⇧actor loss of actor-critic model
User Simulation
It's high cost to get real user behaviors as training data, so we use a simulated user, which is rule-based defined its behavior. To make system more robust, the simulated user sometimes makes error decision as noise.
For each simulation round, simulated user randomly picks a movie from database and covers some information (because real user usually forgets some information of movie), and then asks agent with the remaining information. It is a success when the picked movie is in the movie list which agent returns.
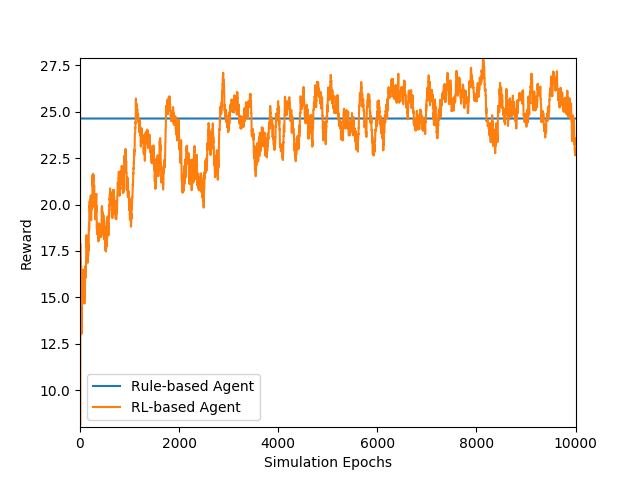
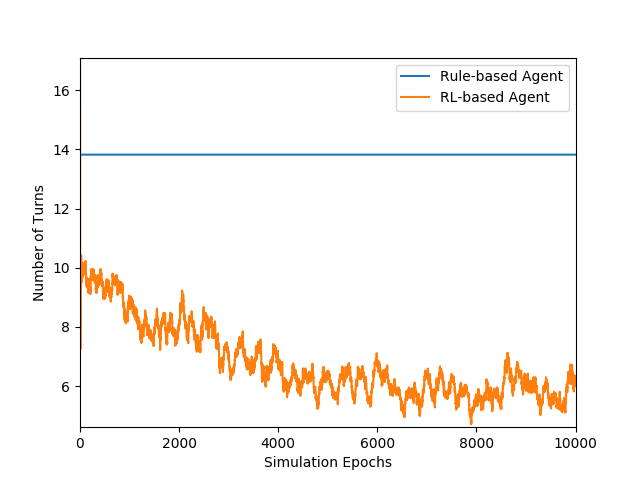
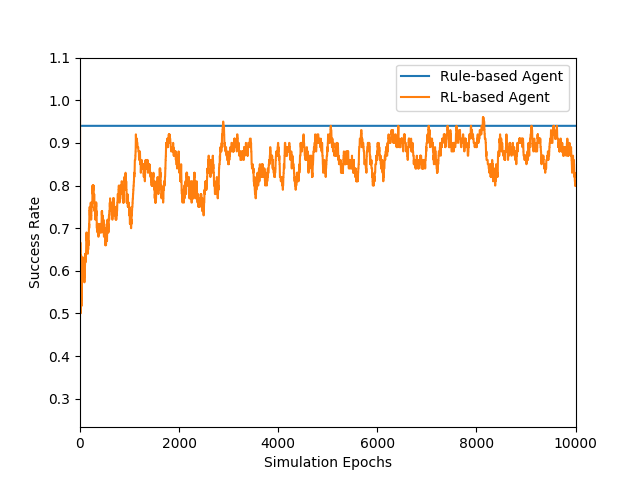
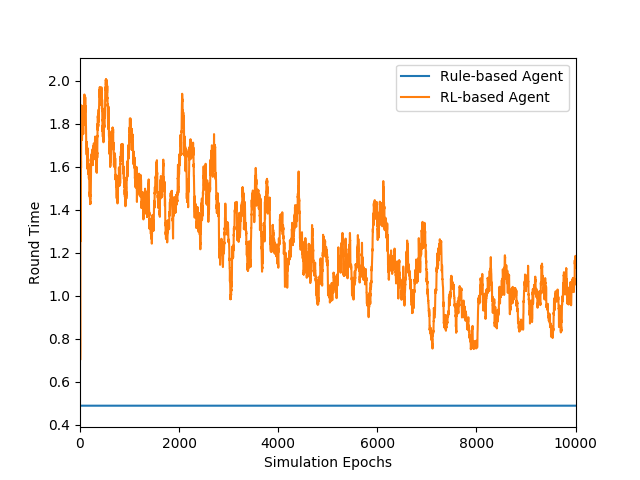
Figures above show the comparison between a rule-based model and our learning-based model. The rule-based model sequetially requests the content of each slot type, and has probabilities to comfirm. Note that the time cost is higher in our leanring-based model because it querys database every turn to get state vector, and the success rate of rule-based model is an upper-bound because it requests every slot type. Success rate of both the models are lower than 1.0 because there are still errors caused by NLU model.
Natural Language Generation
Data Format
For natural language generation, We design several patterns for each agent intent and replace the content place with pre-define slots.
The generated training data has 31 patterns with total 93 sentences and we test the model on 50 human-labelled sentences.
| Encoder Input | (random_integer) | request | title | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Prediction | 你 | 要 | 找 | 的 | _title_ | 是 | 指 | _title_content_ | 嗎 | ? |
Model Description
NLG model has the same structure as NLU model.
The only difference is that NLG model doesn't use the encoder result to predict the input intent.
It only use the decoder part to predict the generated sentence.
And Finally we replace the pre-define slots back to real contents.
| Training | Testing | |
|---|---|---|
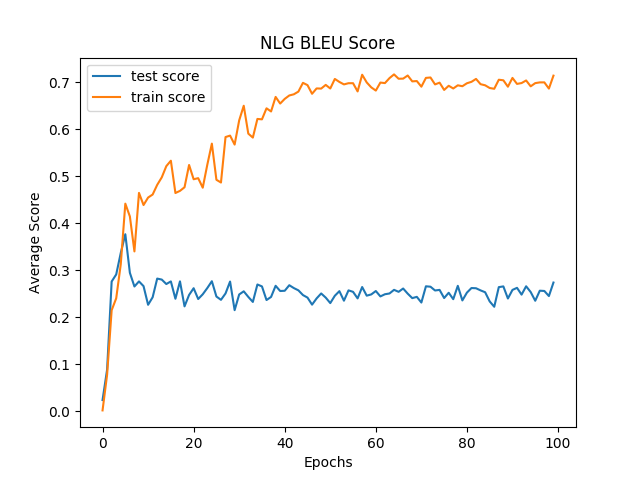
| BLEU Score | 0.7142 | 0.2736 |
⇧NLU BLUE score